Having Fun with Recurrent Neural Networks (RNN)¶
~$ whoami
Sergio G. Burdisso (sergio.burdisso@gmail.com)
~$ pwd
Universidad Nacional de San Luis, Argentina
Having Fun with Recurrent Neural Networks (RNN)¶
~$ cat recommended_readings.txt

RNN Unfolding¶


 (image taken from here)
(image taken from here)
INPUT: $X = X_t\Vert H_{t-1}$
(Where the $\Vert$ operator denotes concatenation)
OUTPUT - NEXT HIDDEN STATE: $H_t = tanh(X\cdot W_H + b_H)$
OPTIONAL OUTPUT - CLASSIFICATION: $Y_t = \sigma(H_t\cdot W + b)$
(where $\sigma$ denotes the $softmax$ function)
 (image taken from here)
(image taken from here)
INPUT:
$X = X_t\Vert H_{t-1}$
$X' = tanh(X\cdot W_c + b_c)$
FORGET GATE: $f = \sigma(X\cdot W_f + b_f)$
UPDATE GATE: $u = \sigma(X\cdot W_u + b_u)$
RESULT GATE: $r = \sigma(X\cdot W_r + b_r)$
LONG-SHORT MEMORY STATE: $C_t = f\odot C_{t-1} + u\odot X'$
(Where $\odot$ denotes element-wise multiplication)
OUTPUT - NEXT HIDDEN STATE: $H_t = r\odot tanh(C_t)$
INPUT:
$X = X_t\Vert H_{t-1}$
$X' = X_t\Vert (r\times H_{t-1})$
$X'' = tanh(X'\cdot W_c + b_c)$
FORGET AND UPDATE GATE: $z = \sigma(X\cdot W_z + b_z)$
RESULT GATE: $r = \sigma(X\cdot W_r + b_r)$
(Note there's 2 Gates instead of 3 = fewer weights!)
OUTPUT - NEXT HIDDEN STATE: $H_t = (1-z)\odot H_{t-1} + z\odot X''$
TASK: Creating our own RNN to generate sequence of characters (using TensorFlow)¶
i.e. Our classifier needs to learn to predict the next character in a sequence!
1. Imports¶
import tensorflow as tf
import numpy as np
from tensorflow.contrib import layers
from tensorflow.contrib import rnn
from idataset import Dataset
2. Hyper-parameters¶
hStateSize = 512 # Number of Hidden Units (NHU) i.e. size of Hidden State Vector
maxSeqLength = 128 # MSL
nLayers = 3 # NL
learningRate = 1e-3 # 0.001
dropoutProb = 0.3
batchSize = 200 # BS
alphaSize = Dataset.get_alphabet_size() # AS
hStateSize = 512 # Number of Hidden Units (NHU) i.e. Size of Hidden State Vector
alphaSize = Dataset.get_alphabet_size(); # AS

nLayers = 3 # NL

maxSeqLength = 128 # MSL
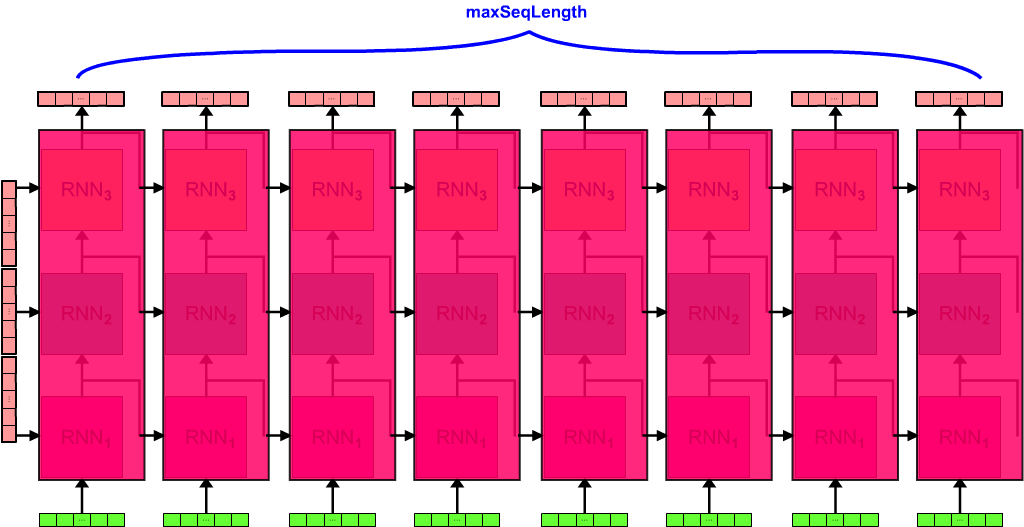
batchSize = 200 # BS

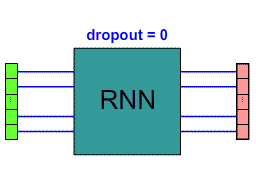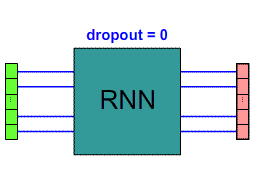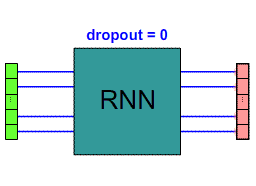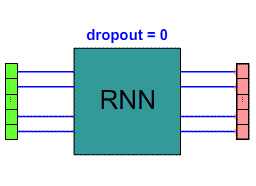
Dropout (> 0)¶
dropoutProb = 0.3


def tf_create_inputs():
global X_train, y_train, h_state_input, dropout, batch_size
X_train = tf.placeholder(tf.uint8, [None, None], name="X_train")
y_train = tf.placeholder(tf.uint8, [None, None], name="y_train")
h_state_input = tf.placeholder(tf.float32, [None, hStateSize * nLayers], name="h_state_input")
dropout = tf.placeholder(tf.float32, name="dropout")
batch_size = tf.placeholder(tf.int32, name="batch_size")

X_train = tf.placeholder(...)
y_train = tf.placeholder(...)
h_state_input = tf.placeholder(...)

def tf_create_architecture():
global rnn_cells_stack_outdropout
rnn_cells = [rnn.GRUCell(hStateSize) for _ in range(nLayers)]
rnn_cells_indropout = [
rnn.DropoutWrapper(cell, input_keep_prob=(1 - dropout))
for cell in rnn_cells
]
rnn_cells_stack = rnn.MultiRNNCell(rnn_cells_indropout, state_is_tuple=False)
rnn_cells_stack_outdropout = rnn.DropoutWrapper(
rnn_cells_stack, output_keep_prob=(1 - dropout)
)
rnn_cells = [rnn.GRUCell(hStateSize) for _ in range(nLayers)]
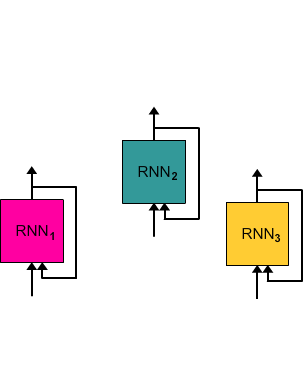
rnn_cells_indropout = [rnn.DropoutWrapper(cell, input_keep_prob=(1 - dropout)) ...]

(Note: dropout only on inputs)
rnn_cells_stack = rnn.MultiRNNCell(rnn_cells_indropout...)

rnn_cells_stack_outdropout = rnn.DropoutWrapper(
..., output_keep_prob=(1 - dropout)
)

(Note: dropout on output)
def tf_graph_forward_propagation():
global h_state_outputs, next_h_state_input, X_train_oh, y_train_oh
X_train_oh = tf.one_hot(X_train, alphaSize, 1.0, 0.0)
y_train_oh = tf.one_hot(y_train, alphaSize, 1.0, 0.0)
h_state_outputs, next_h_state_input = tf.nn.dynamic_rnn(
rnn_cells_stack_outdropout,
X_train_oh,
dtype=tf.float32,
initial_state=h_state_input
)
# named just to be able to use it later, when we restore the graph from disk
# to generate sequences
next_h_state_input = tf.identity(next_h_state_input, name='next_h_state_input')
X_train_oh = tf.one_hot(X_train, alphaSize, 1.0, 0.0)
y_train_oh = tf.one_hot(y_train, alphaSize, 1.0, 0.0)

h_state_outputs, next_h_state_input = tf.nn.dynamic_rnn(
rnn_cells_stack_outdropout,
X_train_oh,
initial_state=h_state_input
)

def tf_graph_fullyconnected_softmax():
global h_state_outputs_flat, y_preds_logit, y_preds_prob
# flatting h_state_outputs
h_state_outputs_flat = tf.reshape(h_state_outputs, [-1, hStateSize])
y_preds_logit = layers.fully_connected(
h_state_outputs_flat,
alphaSize,
activation_fn=tf.nn.relu # the default
# activation_fn=tf.nn.softmax => WARNING: This op expects unscaled logits,
# since it performs a softmax on logits internally for efficiency.
# https://www.tensorflow.org/versions/master/api_docs/python/tf/nn/softmax_cross_entropy_with_logits_v2
)
y_preds_prob = tf.nn.softmax(y_preds_logit, name="y_preds_prob") # (BS*MSL, AS)

h_state_outputs_flat = tf.reshape(h_state_outputs, [-1, hStateSize])

y_preds_logit = layers.fully_connected(h_state_outputs_flat,alphaSize)

def tf_graph_training():
global y_train_oh_flat, loss, train_step
y_train_oh_flat = tf.reshape(y_train_oh, [-1, alphaSize])
loss = tf.nn.softmax_cross_entropy_with_logits(logits=y_preds_logit, labels=y_train_oh_flat)
loss = tf.reshape(loss, [batch_size, -1])
# Backpropagation
# Adam paper: https://arxiv.org/pdf/1412.6980.pdf
train_step = tf.train.AdamOptimizer(learningRate).minimize(loss)
y_train_oh_flat = tf.reshape(y_train_oh, [-1, alphaSize])
loss = tf.nn.softmax_cross_entropy_with_logits(
logits=y_preds_logit, labels=y_train_oh_flat
)
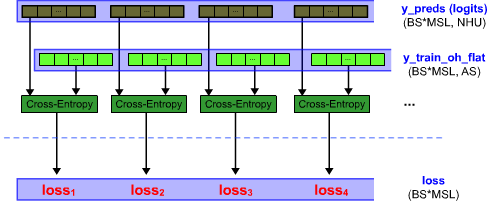
loss = tf.reshape(loss, [batch_size, -1])
train_step = tf.train.AdamOptimizer(learningRate).minimize(loss)

(backward propagation of errors)
4. Training (1/2)¶
def tf_init_session():
config = tf.ConfigProto()
config.gpu_options.allow_growth = True # only needed when using GPU
sess = tf.Session(config=config)
sess.run(tf.global_variables_initializer())
return sess
4. Training (2/2)¶
def train(pattern_path, trained_model_name, n_epochs=20):
from time import time
dataset = Dataset.load_from_files(pattern_path)
sess = tf_init_session()
n_chars_processed = 0
oepoch = -1
t_start = time()
# initial input hidden state (zero)
in_h_state = np.zeros([batchSize, hStateSize * nLayers])
try:
print("[training] starting to learn :) ...")
for epoch, X_train_batch, y_train_batch in Dataset.get_training_batches(
n_epochs, batchSize, maxSeqLength, dataset
):
_, next_in_h_state = sess.run(
[train_step, next_h_state_input],
feed_dict={
X_train: X_train_batch, y_train: y_train_batch, h_state_input: in_h_state,
dropout: dropoutProb, batch_size: batchSize
}
)
in_h_state = next_in_h_state
n_chars_processed += batchSize * maxSeqLength
if oepoch != epoch:
oepoch = epoch
print(
"[training][epoch %d/%d] characters processed: %d" %
(epoch + 1, n_epochs, n_chars_processed)
)
except KeyboardInterrupt:
pass
print("[training] training finished (%.1f mins)" % ((time() - t_start) / 60))
saved_file = tf.train.Saver().save(sess, 'trained_models/test/%s' % trained_model_name)
print("[training] model saved: " + saved_file)
4. Training (2/2) - The training loop¶
# initial input hidden state (zero)
in_h_state = np.zeros([batchSize, hStateSize * nLayers])
for epoch, X_train_batch, y_train_batch in Dataset.get_training_batches(...):
_, next_in_h_state = sess.run(
[train_step, next_h_state_input],
feed_dict={
X_train: X_train_batch, y_train: y_train_batch, h_state_input: in_h_state,
dropout: dropoutProb, batch_size: batchSize
}
)
in_h_state = next_in_h_state
for epoch, X_train_batch, y_train_batch in Dataset.get_training_batches(
n_epochs, batchSize, maxSeqLength, dataset
):

4. Sequence Generator¶
def generate_seq(model_path, seq_start="a", length=1000):
tf.reset_default_graph()
output_seq = seq_start
sess = tf_init_session()
with sess:
try:
saver = tf.train.import_meta_graph(model_path + '.meta')
except OSError:
print("[generate_seq] model %s does not exist" % model_path)
return seq_start
saver.restore(sess, model_path)
in_X = Dataset.encode_str(output_seq)
in_X = np.array([in_X]) # "1 bach of 1 sequence"
# initial input hidden state (zero)
in_h_state = np.zeros([1, hStateSize * nLayers], dtype=np.float32)
for i in range(length):
y_preds_prob, next_in_h_state = sess.run(
['y_preds_prob:0', 'next_h_state_input:0'],
feed_dict={
'X_train:0': in_X,
'h_state_input:0': in_h_state,
'dropout:0': 0., 'batch_size:0': 1
}
)
in_h_state = next_in_h_state
char = Dataset.peek_char_from_prob(y_preds_prob[-1], top_n=2)
in_X = np.array([[char]]) # "1 bacth of 1 sequence of 1 char"
output_seq += Dataset.decode_char(char)
return output_seq
Generator loop¶
# initial input hidden state (zero)
in_h_state = np.zeros([1, hStateSize * nLayers], dtype=np.float32)
for i in range(length):
y_preds_prob, next_in_h_state = sess.run(
['y_preds_prob:0', 'next_h_state_input:0'],
feed_dict={
'X_train:0': in_X,
'h_state_input:0': in_h_state,
'dropout:0': 0., 'batch_size:0': 1
}
)
in_h_state = next_in_h_state
char = Dataset.peek_char_from_prob(y_preds_prob[-1], top_n=2)
in_X = np.array([[char]]) # "1 bacth of 1 sequence of 1 char"
5. Gluing it all together¶
# This function will give life to our RNN
def tf_work_your_magic():
tf.reset_default_graph() # we're gonna make magic more than once! XD
tf_create_inputs()
tf_create_architecture()
tf_graph_forward_propagation()
tf_graph_fullyconnected_softmax()
tf_graph_training()
Let the fun begin...¶
- Learning to "payar" (going The Martin Fierro's way).
- Learning to compose some music.

1. Let's learn how to payar!¶

Aquí me pongo a cantar
al compás de la vigüela,
que el hombre que lo desvela
una pena estrordinaria,
como la ave solitaria
con el cantar se consuela.
Pido a los santos del cielo
que ayuden mi pensamiento:
...
mfierro_path = "dataset/martinfierro/"
mfierro_files = mfierro_path + "*.txt"
# NOTE: We need to run this code below only once
Dataset.encode_files(mfierro_files, target_codec="utf8")
Dataset.normalize_files(mfierro_files)
# making sure our RNN is alive
tf_work_your_magic()
train(mfierro_files, input("model name: "), n_epochs=5)
# NOTE: if it's taking too long, just press:
# <Esc> and then <I> twice to interrupt
# the process and save the model
canto = generate_seq(
model_path=input("Trained model path: "),
seq_start=input("Sequence starts with: "),
length=1000
)
print(canto)
from re import sub as re_replace
trained_epochs = [0, 50, 400]
trained_model = "trained_models/martinfierro/%depochs" % trained_epochs[-1]
canto = generate_seq(model_path=trained_model, seq_start=input("Starts with: "), length=1000)
canto = re_replace(r'\d:\s', '', canto) # deleting all :1,:2,:3... etc.
print(canto)

The ABC Notation (http://abcnotation.com/)¶
Example:
X: 1
T: Cooley's
M: 4/4
L: 1/8
R: reel
K: Emin
Q:120
|:D2|EB{c}BA B2 EB|~B2 AB dBAG|FDAD BDAD|FDAD dAFD|
EBBA B2 EB|B2 AB defg|afe^c dBAF|DEFD E2:|
|:gf|eB B2 efge|eB B2 gedB|A2 FA DAFA|A2 FA defg|
eB B2 eBgB|eB B2 defg|afe^c dBAF|DEFD E2:|Good tutorial: How to interpret abc music notation
Playing ABC files¶
Software: http://abcnotation.com/software
Webplayer: https://abcjs.net/abcjs-editor.html
But we're gonna be using these commands: abcmidi, timidity.
Installation:
~$ sudo apt install abcmidi
~$ sudo apt-get install timidity timidity-interfaces-extraUsage:
~$ abc2midi song.abc -o song.mid
~$ timidity song.midmusic_path = "dataset/music/"
music_files = music_path + "**/*.[ta][xb][tc]" # Recursively, all .abc or .txt files
# NOTE: We need to run this code below only once
Dataset.encode_files(music_files, target_codec="utf8")
Dataset.normalize_files(music_files)
# making sure our RNN is alive
tf_work_your_magic()
train(music_files, input("model name: "), n_epochs=1)
# WARNING: this dataset is 12,703,923 chars long...
# so each epoch is going to take a while.
# NOTE: if it's taking too long, just press:
# <Esc> and then <I> twice to interrupt
# the process and save the model
def play(str_abc):
from os import system
tmp_song = "_tmp_song.abc"
with open(tmp_song, "w") as abc_song:
abc_song.write(str_abc)
system('bash play_abc.bash ' + tmp_song)
song = generate_seq(
model_path=input("Trained model path: "),
seq_start=input("Sequence starts with: "),
length=1000
)
print(song)
play(song)
# NOTE: press <Esc> and then <I> twice to stop playing
from re import sub as re_replace
trained_epochs = [0, 5, 10, 15, 20]
trained_model = "trained_models/music/%depochs" % trained_epochs[-1]
song = generate_seq(model_path=trained_model, seq_start="X:", length=1500)
print(song)
play(song) # (shake it)^n
# NOTE: press <Esc> and then <I> twice to stop playing
